
Pirkko Suihkonen
Dosentti, yleisen kielitieteen laitos, Helsingin yliopisto
Tutkija, Max Planck Institute for Evolutionary Anthropology
Kaikissa tunnetuissa kielissä on ainakin joitakin lukumäärää merkitseviä sanoja. Köyhin järjestelmä on tunnistettu eräässä Tasmaniassa puhuttavassa kielessä, jossa erotetaan luvut 1, 2 ja 2 + 1, jolla on merkitys 'monta'. Uudessa Guineassa on kieliä, joissa lasketaan kymmeneen yhdistämällä muutamia peruslukusanoja: 1, 2, 2 + 1, 4, 4 + 1, 4 + 2, 4 + (2 + 1), 4 + (2 + 2), 4 + (2 + 1) + 2 ja 10 (Sasse 1999).
Varsin yleistä on, että laskemisjärjestelmän kehittymisvaiheessa on hyödynnetty sormia ja varpaita ja myös muita ruumiinjäseniä lukumäärän määrittelyn apuna. Haruaissa, jota puhutaan Uudessa Guineassa, on käytössä kolme lukujärjestelmää. Vanhin järjestelmä käsittää vain kaksi jäsentä, morfeemit, joilla on merkitykset 'yksi' ja 'kaksi'. Kahta suurempia lukuja muodostetaan yhdistämällä tai reduplikoimalla näitä kahta peruselementtiä. Toinen järjestelmä on ruumiin jäsenten laskemisen avulla muodostettu järjestelmä, jossa lasketaan tavallisesti vasemman käden pikkusormesta lähtien aina 18:aan, jota osoitetaan oikean käden ranteella, ja sitten taas takaisin 36:een. Tämä järjestelmä on käytössä myös Haruain naapurikielessä. Kolmas käytössä oleva järjestelmä on alueella puhuttavan pidginenglannin numerojärjestelmä, jota käytetään myös puhuttaessa 30:a suuremmista luvuista (Comrie 1999). Eräässä mikronesialaisessa kielessä on käytössä oma lukujärjestelmänsä kalojen ja kaikkeen kaloihin liittyvän laskemiseen ja toinen lukujärjestelmä, jota käytetään kaikkea muuta laskettaessa (Hurdford 1987: 165). Eri lukujärjestelmien käytöstä eri tarkoituksiin on esimerkkinä binäärijärjestelmän hyödyntäminen sähköisessä tiedonvälityksessä.
Suomessa, kuten monissa muissakin kielissä, lukusanat muodostavat suljetun sanaluokan, jossa uusia sanoja muodostetaan tietyistä peruselementeistä erilaisten operaatioiden avulla. Lukusanojen lisäksi kielissä on myös määrää osoittavia pronomineja ja pronominaalisesti käytettyjä adjektiiveja (suomen kielessä tällaisia ovat esimerkiksi pronominit moni, muutama, jokainen tai substantiivi pari, joka käyttäytyy kuten lukusanat).
Kielentutkimuksessa voidaan tutkia lukusanoja hyvin eri tavoin ja erilaisista näkökulmista. Kielihistorian tutkijat tutkivat sitä, miten lukusanat ovat muodostuneet ja kehittyneet, ja millainen suhde niillä on kieltä puhuvan väestön kulttuuriin. Teoreettinen kielitiede on kiinnostunut mm. siitä, millaisia järjestelmiä, rakenteita, sääntöjä ja suhteita lukusanoihin, määrää osoittaviin pronomineihin ja lukujärjestelmiin liittyy. Myös varsinaisissa lukujärjestelmissä on suuria eroja, vaikka lukujärjestelmien perustyypit, kuten länsimaisissa käytössä oleva kymmenjärjestelmä, ovatkin levinneet laajalle.
Uralilaiset kielet jaetaan perinteisesti suomalais-ugrilaisiin ja samojedikieliin:
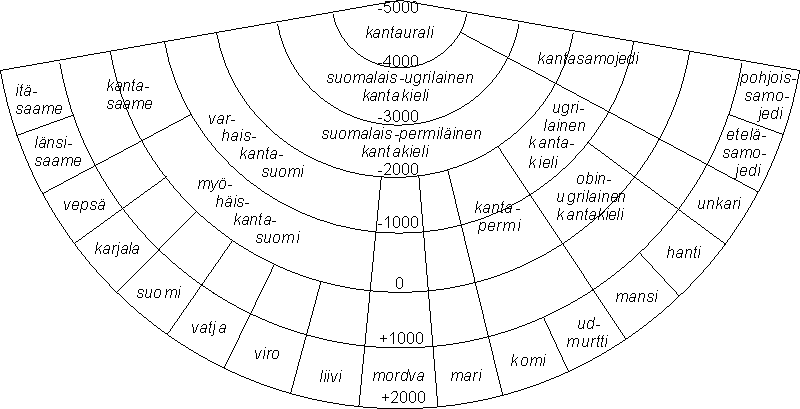
Kuva 1: Kaavio vielä elävien suomensukuisten kielten keskinäisistä suhteista. Kuvio mallintaa kielihistoriallisen ja vertailevan menetelmän avulla rekonstruoituja uralilaisten kielten välisiä suhteita. Kaavio ei kerro mitään uralilaisia kieliä puhuvien kansojen ja kansanryhmien geneettisestä alkuperästä tai sukulaisuudesta. Alkuperäinen kaavio on Tiedekeskus Heurekassa oleva kartio, jossa värien asteittaisen vaihtumisen avulla on pyritty osoittamaan se, että kantakielten eriytyminen tytärkieliksi on pitkä prosessi, jossa kielen muuttumisen eri vaiheiden suhdetta siihen, milloin voidaan saman kielen murteiden sijasta puhua eri kielistä, on vaikea osoittaa. Mitä kauemmaksi ajassa taaksepäin siirrytään, sitä vähemmän variaatiota voidaan rekonstruoituihin kielihistoriallisiin muotoihin liittää. Eri lähestymistavat ja eri tutkimukset eroavat huomattavasti toisistaan uralilaisten kielten eri kantakielten ikien määrittelyssä. Viimeisten tutkimusten mukaan esim. suomalais-saamelaisen kantakielen (varhaiskantasuomen) eroamisvaihe ajoitetaan n. 2500 eKr.
Huom. On olemassa paljon muitakin kaavioita, jotka on tehty kuvaamaan uralilaisten kielten sukulaisuussuhteita. Sukupuukaavio on niistä yleisin.
Kielihistorian tutkijat ovat osoittaneet, että lukusana kaksi on uralilaisissa kielissä yhteistä alkuperää. Tällä tarkoitetaan sitä, että sana voidaan johtaa kielihistoriallista tutkimusmenetelmää käyttäen suomalais-ugrilaisiin ja samojedikieliin. Myös lukusanoille \emphseitsemän ja viisi on esitetty uralilaiseen kantakieleen periytyvää historiaa.
Yhteisiä suomalais-ugrilaisia sanoja on sen sijaan enemmän: lukusanat yhdestä kuuteen ovat suomalais-ugrilaisissa kielissä yhteistä alkuperää, ja myös joidenkin muiden lukusanojen on esitetty voitavan johtaa yhteiseen suomalais-ugrilaiseen kantakieleen. Tällainen on lukusana kymmenen (10), joka on yhteistä alkuperää saamessa, marissa ja mansissa (suomen kielen substantiivilla luku on sama alkuperä). Lukusanan seitsemän yhteinen historia voidaan johtaa ainakin itämerensuomalaisiin kieliin, saameen, mordvaan, mariin, komiin ja udmurttiin (Taulukko 1).
Taulukossa 1 on lueteltu useimpien suomalais-ugrilaisten kielten lukusanat yhdestä kymmeneen. Samojedikielistä ovat mukana nenetsi ja selkuppi. Monien lukusanojen yhteenkuuluvuus on helppo tunnistaa. Mielenkiintoisia ovat lukusanat yhdeksän ja kahdeksan. Esim. suomen lukusanojen yhdeksän ja kahdeksan on varhemmin selitetty muodostuneen siten, että niiden perusosan muodosti latinan sanaan decem '10' johdettava sana, josta oli vähennetty lukusanat yksi ja kaksi: "yksi pois kymmenestä" ja "kaksi pois kymmenestä". (Tällä tavoin selitetään udmurtin ja komin kahdeksaa ja yhdeksää tarkoittavien lukusanojen historia.) Nyttemmin suomen lukusanoissa kahdeksan ja yhdeksän selitetään olevan taustalla lukusanat yksi ja kaksi ja kieltoverbin ei johdannainen: "yhtä ei ole" ja "kahta ei ole". Tätäkään etymologiaa ei pidetä virheettömänä. Lukusanoissa on myös muista kielistä saatuja lainoja: esimerkiksi udmurtin ja komin das '10' on iranilaista alkuperää.
Taulukossa 2 on esimerkkejä uralilaisten kielten lukusanoista 11-20. Tässä ryhmässä uusien lukusanojen muodostamisen perustyypit suomalais-ugrilaisissa kielissä ovat lisääminen, vähentäminen, kertominen ja jakaminen. Myös näiden kaikkien ryhmien sisällä on melkoista variaatiota. Lisääminen voidaan tehdä esim. yhdistämällä numeraalit siten, että kymmeneen lisätään ykköset, jotka ovat yli kymmenen, kuten esim. udmurtissa: das kyk '12', käyttämällä koordinatiivista konjunktiota kuten karjalassa: kymmenen da kaksi '12', tai adverbiaalirakenteen avulla kuten vanhassa kirjasuomessa: caxi päälle yhdexänkymmenen '92'. Suomen lukusanoissa 11:stä 20:een on partitiivisuffiksi: yksitoista(-kymmentä) = yksi toisesta kymmenestä, saamessa taas latiivisuffiksi: guokte-nuppe-lohkái '12'. Vähentämällä muodostetuista numeraaleista ovat esimerkkinä komin ja udmurtin kahdeksan ja yhdeksän. Jakamisesta on esimerkkinä viron peel kolmat sada '250' ('puoli kolmatta sataa') ja kertomisesta vanhentunut komipermjakin muoto das'-jec-das '100' ('kymmenen kertaa kymmenen'; perusteellinen selvitys uralilaisten kielten lukusanoista on László Hontin teoksessa Die Grundzahlwörter der uralischen Sprachen, josta myös useimmat artikkelissa olevista esimerkeistä on otettu). Lukusanan 20 etymologia on yhteinen udmurtissa, komissa, hantissa, mansissa ja unkarissa. Samaa kantaa oleva sana viittaa ihmiseen, esim. mansi: xum 'mies (ihminen; sellainen, jolla on sormet ja varpaat)'.
Taulukossa 3 on uralilaisten kielten täysiä kymmeniä merkitseviä lukusanoja sekä lukusanat sata, tuhat ja miljoona. Kaikissa suomalais-ugrilaisissa kielissä on indoeurooppalaista alkuperää oleva lukusana sata. Komin, udmurtin, hantin ja mansin tuhatta merkitsevän sanan on esitetty olevan alkujaan indo-arjalainen, ja sana tuhat taas on osoitettu alkuperältään balttilaiseksi.
Taulukko 1 (PDF): Uralilaisten kielten lukusanoja 1-10. (Kielten lyhenteet: Komi = komisyrjääni, Nen = tundranenetsi, Mari = itämari, PohjS = pohjoissaame, Selk = selkuppi, Udm = udmurtti, Unk = unkari. Luettelossa kielten lukusanat suomesta unkariin on otettu näiden kielten kieliopeista. Nenetsin ja selkupin lukusanat ovat näiden kielten murremuotoja.)
Taulukko 2 (PDF): Uralilaisten kielten lukusanoja 11-20.
Taulukko 3 (PDF): Uralilaisten kielten lukusanoja: kymmenet, sata, tuhat ja miljoona.
Nykyisissä uralilaisissa kielissä, joihin myös suomi kuuluu, on käytössä kymmenjärjestelmä. Koska kymmenjärjestelmä on kaikissa uralilaisissa kielissä, onkin kysytty, onko kymmenjärjestelmä ollut jo uralilaisessa kantakielessä. Kuitenkin se, voidaanko tämä johtaa ehkä noin 6000-7000 vuoden taakse, on varsin epävarmaa. Yhteiseen kantakieleen on postuloitu useitakin lukujärjestelmiä (Honti 1999). Sen perusteella, että lukusana kaksi on yhteinen uralilaisissa kielissä, on arveltu tämän viittaavan siihen, että myös uralilaisessa kantakielessa oli käytössä lukujärjestelmä, jossa oli vain luvut yksi ja kaksi. Suomalais-ugrilaisissa kielissä on yhteiset lukusanat yhdestä kuuteen, ja tämän taas on katsottu viittaavan siihen, että käytössä on ollut kuusijärjestelmä. Uralilaisesta kantakielestä on yritetty etsiä myös muita järjestelmiä, mm. kaksikymmen- ja kuusikymmenjärjestelmät. Yhteiseen laskemisjärjestelmään viittaavia elementtejä on esitetty olevan myös lukusanan seitsemän käytössä ns. maagisena lukuna.
Sen puolesta, että kymmenjärjestelmä olisi ollut jo suomalais-ugrilaisessa kantakieliessä, puhuu se, että permiläisissä ja ugrilaisissa kielissä on kymmentä suurempia kymmenlukuja merkitsevät lukusanat muodostettu sanaan kymmenen johdettavilla, eri ikäisillä kielen aineksilla: esim. komi: kvajty-myn '60', sizim-das '70'; mansi: xot-pan '60', sat-low '70', unkari: harm-inc, murteellinen muoto: harm-ic <*armu '3' + tizü '10') '30', and negy-ven '40'. Mansin low-, unkarin tíz- ja komin ja udmurtin das-lukusanoilla on merkitys '10', ja komin ja udmurtin myn ja hantin pan, man, ja unkarin suffiksilla van, ven on myös kymmeneen johtava kielihistoriallinen kehitys takanaan. Ainakaan sitä ei ole voitu osoittaa, että kymmenjärjestelmä ei olisi ollut jo suomalais-ugrilaisessa kantakielessä tai kantasamojedissa.
Comrie, Bernard. 1999. Haruai Numerals and their Implications for the History and Typology of Numeral Systems. Teoksessa Gvozdanovic, Jadranka (toim.): Numeral Types and Changes Worldwide. Trends in Linguistics. Studies and Monographs 118. Mouton de Grueter. Berlin & New York. 82-94.
Honti, László. 1993. Die Grundzahlwörter der uralischen Sprachen. Bibliotheca Uralica. Akadémiai kiadó. Budapest.
Honti, László. 1999. The Numeral System of the Uralic Languages. Teoksessa Gvozdanovic, Jadranka (toim.): Numeral Types and Changes Worldwide. Trends in Linguistics. Studies and Monographs 118. Mouton de Grueter. Berlin & New York. 243-252.
Hurford, James H. 1987. Language and number. The Emergence of a Cognitive System. Basic Blackwell. Oxford.
Sasse, Hans-Jürgen. 1999. Syntactic Categories and Subcategories. Teoksessa Jacobs, Joachim & al (toim): Syntax. Ein internationales Handbuch zeitgenössischer Forschung. Mouton de Grueter. Berlin. 646-686.
Suomen kielen etymologinen sanakirja, Suomalais-Ugrilainen seura, 1981-1987.
Suomen sanojen alkuperä. SKS, 1992, 1995, 2000.
http://www.zompist.com/numbers.shtml
Tietoa lukujärjestelmistä ja niiden kehityksestä on mm. Encyclopaedia Britannicassa:
http://www.britannica.com/bcom/eb/article/2/0,5716,57902+1+56491,00.html